How does MapReduce shuffle work?
What is MapReduce Shuffling and Sorting? Shuffling is the process by which it transfers mappers intermediate output to the reducer. Reducer gets 1 or more keys and associated values on the basis of reducers. The intermediated key – value generated by mapper is sorted automatically by key.
What are the steps involved in MapReduce counting?
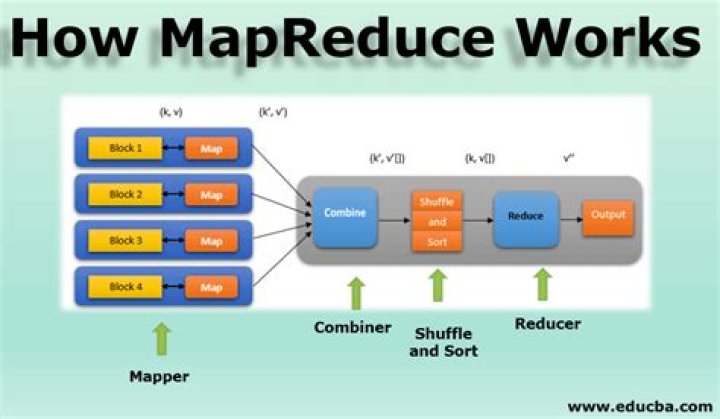
How MapReduce Works
- Map. The input data is first split into smaller blocks.
- Reduce. After all the mappers complete processing, the framework shuffles and sorts the results before passing them on to the reducers.
- Combine and Partition.
- Example Use Case.
- Map.
- Combine.
- Partition.
- Reduce.
Which function performs shuffling and sorting in chunks?
Once the data is shuffled to the reducer node the intermediate output is sorted based on key before sending it to reduce task. The algorithm used for sorting at reducer node is Merge sort. The sorted output is provided as a input to the reducer phase. Shuffle Function is also known as “Combine Function”.
What are some of the advantages of shuffling and sorting between a map and reduce task?
Shuffling can start even before the map phase has finished, to save some time. That’s why you can see a reduce status greater than 0% (but less than 33%) when the map status is not yet 100%. Sorting saves time for the reducer, helping it easily distinguish when a new reduce task should start.
Which of the following tasks is done by Shuffle phase in MapReduce?
Shuffle phase in Hadoop transfers the map output from Mapper to a Reducer in MapReduce. Sort phase in MapReduce covers the merging and sorting of map outputs. Data from the mapper are grouped by the key, split among reducers and sorted by the key.
What is combiner and partitioner in MapReduce?
The difference between a partitioner and a combiner is that the partitioner divides the data according to the number of reducers so that all the data in a single partition gets executed by a single reducer. However, the combiner functions similar to the reducer and processes the data in each partition.
What is mapper and reducer?
Hadoop Mapper is a function or task which is used to process all input records from a file and generate the output which works as input for Reducer. Mapper is a simple user-defined program that performs some operations on input-splits as per it is designed.
What is combiner in MapReduce?
Advertisements. A Combiner, also known as a semi-reducer, is an optional class that operates by accepting the inputs from the Map class and thereafter passing the output key-value pairs to the Reducer class. The main function of a Combiner is to summarize the map output records with the same key.
What is shuffling in MapReduce Mcq?
Shuffling in MapReduce The process of transferring data from the mappers to reducers is known as shuffling i.e. the process by which the system performs the sort and transfers the map output to the reducer as input.
What is shuffling in spark?
In Apache Spark, Spark Shuffle describes the procedure in between reduce task and map task. Shuffling refers to the shuffle of data given. This operation is considered the costliest. Parallelising effectively of the spark shuffle operation gives performance output as good for spark jobs.
Which of the given phases appears simultaneously 1 Shuffle and map 2 shuffle and sort 3 reduce and sort 4 map and reduce?
Explanation: The shuffle and sort phases occur simultaneously; while map-outputs are being fetched they are merged. 8. Mapper and Reducer implementations can use the ________ to report progress or just indicate that they are alive.
What happens during the shuffle phase?
Shuffle phase in Hadoop transfers the map output from Mapper to a Reducer in MapReduce. Sort phase in MapReduce covers the merging and sorting of map outputs. Data from the mapper are grouped by the key, split among reducers and sorted by the key. Every reducer obtains all values associated with the same key.
